ERNIE Bot | GitHub | Hugging Face | BAIDU AI Studio | Technical Report
Introduction to ERNIE 4.5
We introduce ERNIE 4.5, a new family of large-scale multimodal models comprising 10 distinct variants. The model family consist of Mixture-of-Experts (MoE) models with 47B and 3B active parameters, with the largest model having 424B total parameters, as well as a 0.3B dense model. For the MoE architecture, we propose a novel heterogeneous modality structure, which supports parameter sharing across modalities while also allowing dedicated parameters for each individual modality. This MoE architecture has the advantage to enhance multimodal understanding without compromising, and even improving, performance on text-related tasks. All of our models are trained with optimal efficiency using the PaddlePaddle deep learning framework, which also enables high-performance inference and streamlined deployment for them. We achieve 47% Model FLOPs Utilization (MFU) in our largest ERNIE 4.5 language model pre-training. Experimental results show that our models achieve state-of-the-art performance across multiple text and multimodal benchmarks, especially in instruction following, world knowledge memorization, visual understanding and multimodal reasoning. All models are publicly accessible under Apache 2.0 to support future research and development in the field. Additionally, we open source the development toolkits for ERNIE 4.5, featuring industrial-grade capabilities, resource-efficient training and inference workflows, and multi-hardware compatibility.

ERNIE 4.5 Highlights
Our model family is characterized by three key innovations:
-
Multimodal Heterogeneous MoE Pre-Training: Our models are jointly trained on both textual and visual modalities to better capture the nuances of multimodal information and improve performance on tasks involving text understanding and generation, image understanding, and cross-modal reasoning. To achieve this without one modality hindering the learning of another, we designed a heterogeneous MoE structure, incorporated modality-isolated routing, and employed router orthogonal loss and multimodal token-balanced loss. These architectural choices ensure that both modalities are effectively represented, allowing for mutual reinforcement during training.
-
Scaling-Efficient Infrastructure: We propose a novel heterogeneous hybrid parallelism and hierarchical load balancing strategy for efficient training of ERNIE 4.5 models. By using intra-node expert parallelism, memory-efficient pipeline scheduling, FP8 mixed-precision training and finegrained recomputation methods, we achieve remarkable pre-training throughput. For inference, we propose multi-expert parallel collaboration method and convolutional code quantization algorithm to achieve 4-bit/2-bit lossless quantization. Furthermore, we introduce PD disaggregation with dynamic role switching for effective resource utilization to enhance inference performance for ERNIE 4.5 MoE models. Built on PaddlePaddle, ERNIE 4.5 delivers high-performance inference across a wide range of hardware platforms.
-
Modality-Specific Post-Training: To meet the diverse requirements of real-world applications, we fine-tuned variants of the pre-trained model for specific modalities. Our LLMs are optimized for general-purpose language understanding and generation. The VLMs focuses on visuallanguage understanding and supports both thinking and non-thinking modes. Each model employed a combination of Supervised Fine-tuning (SFT), Direct Preference Optimization (DPO) or a modified reinforcement learning method named Unified Preference Optimization (UPO) for post-training.
Performance and Benchmark Results
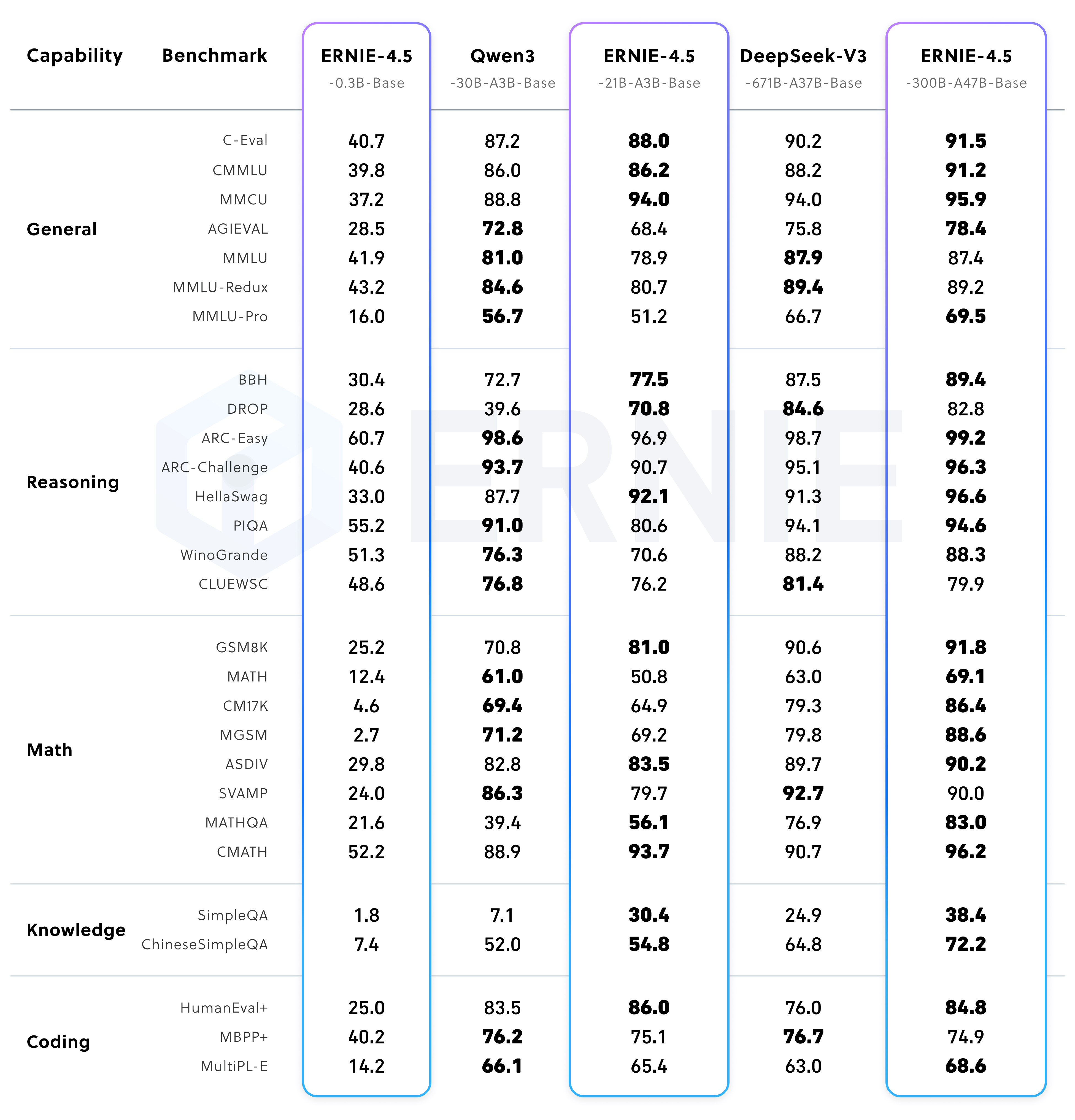
ERNIE-4.5-300B-A47B-Base surpasses DeepSeek-V3-671B-A37B-Base on 22 out of 28 benchmarks, demonstrating leading performance across all major capability categories. This underscores the substantial improvements in generalization, reasoning, and knowledge-intensive tasks brought about by scaling up the ERNIE-4.5-Base model relative to other state-of-the-art large models. With a total parameter size of 21B (approximately 70% that of Qwen3-30B), ERNIE-4.5-21B-A3B-Base outperforms Qwen3-30B-A3B-Base on several math and reasoning benchmarks, including BBH and CMATH. ERNIE-4.5-21B-A3B-Base remains highly competitive given its significantly smaller model size, demonstrating notable parameter efficiency and favorable performance trade-offs.
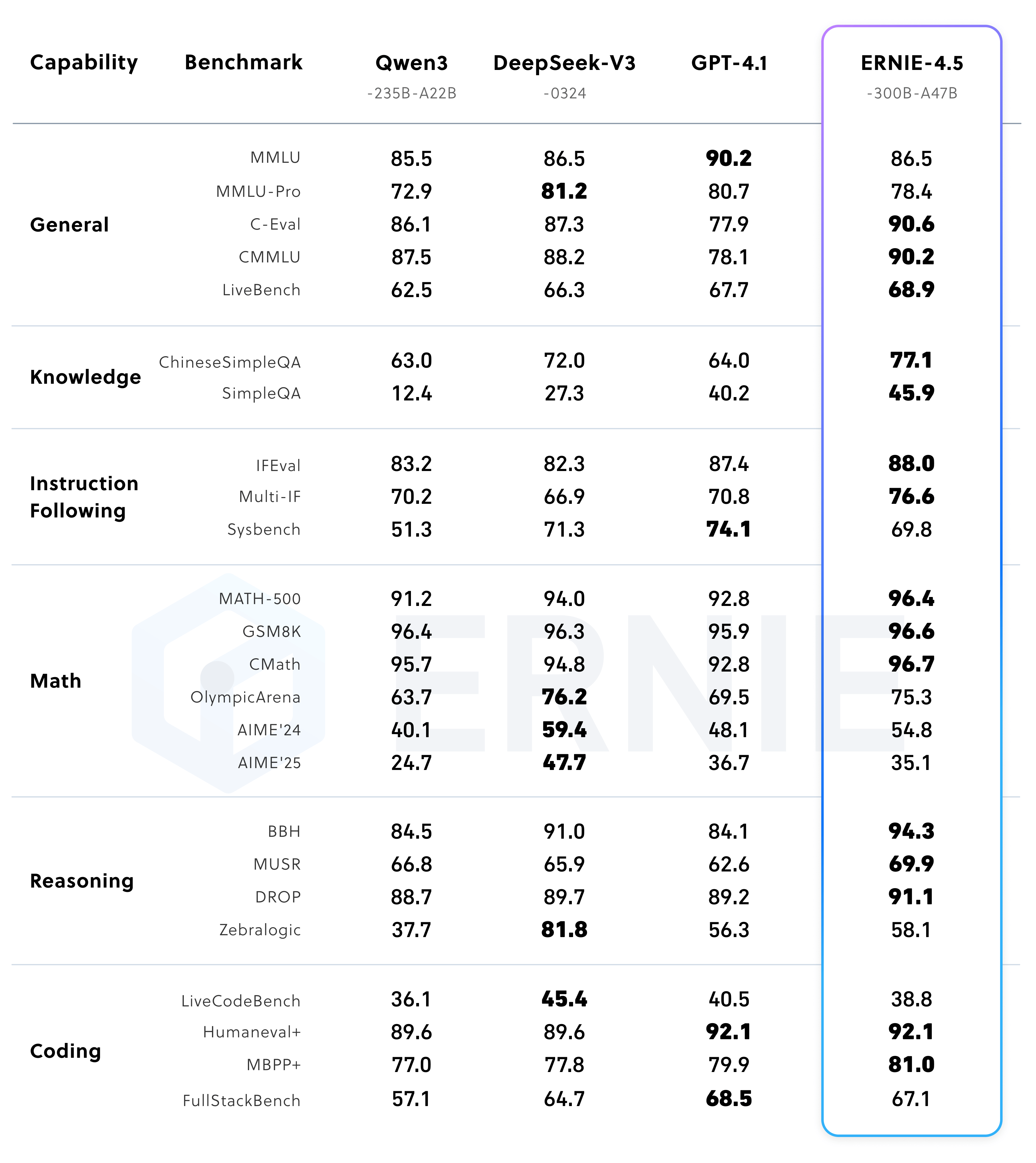
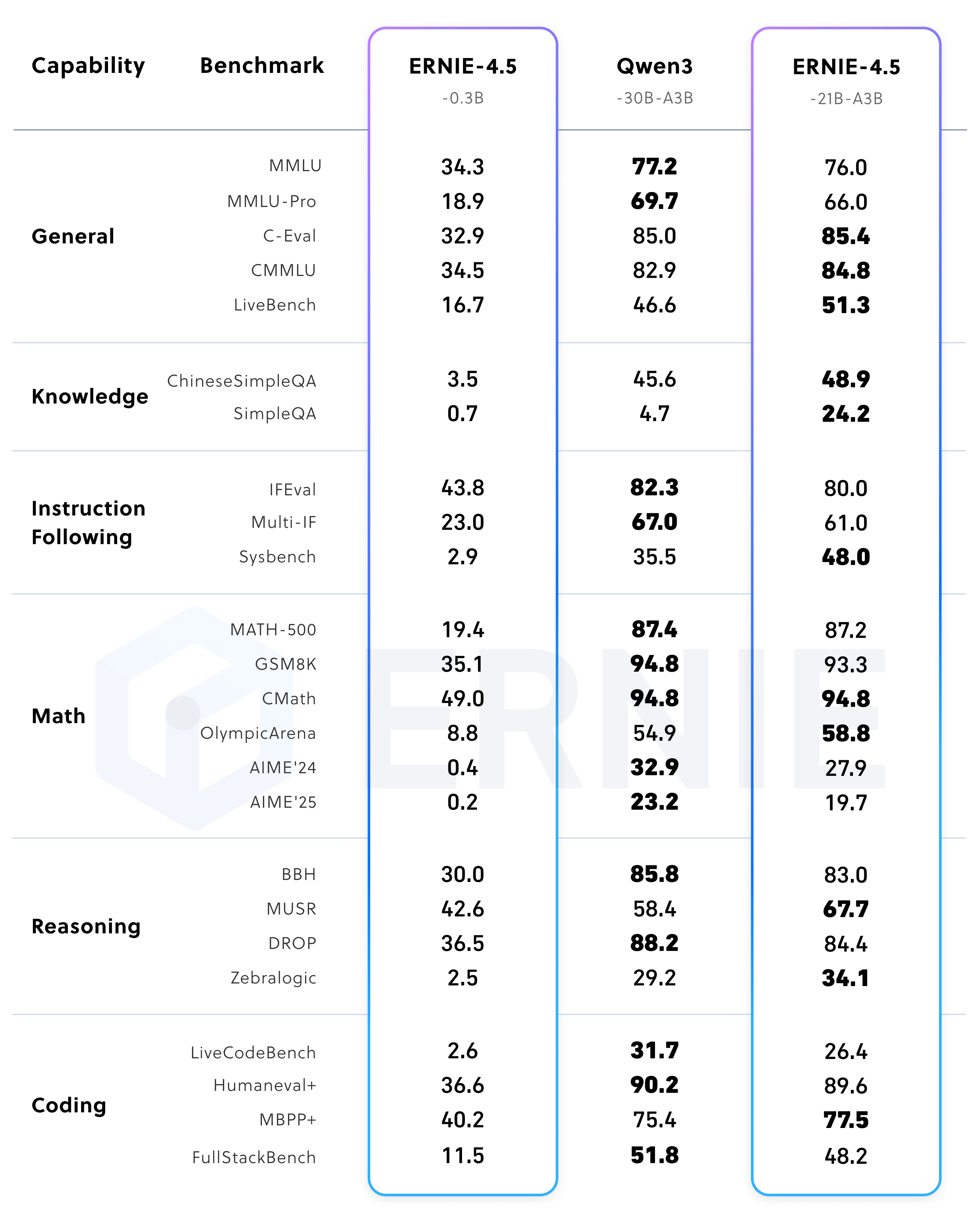
ERNIE-4.5-300B-A47B, the post trained model, demonstrates significant strengths in instruction following and knowledge tasks, as evidenced by the state-of-the-art scores on benchmarks such as IFEval, Multi-IF, SimpleQA, and ChineseSimpleQA. The lightweight model ERNIE-4.5-21B-A3B achieves competitive performance compared to Qwen3-30B-A3B, despite having approximately 30% fewer total parameters.
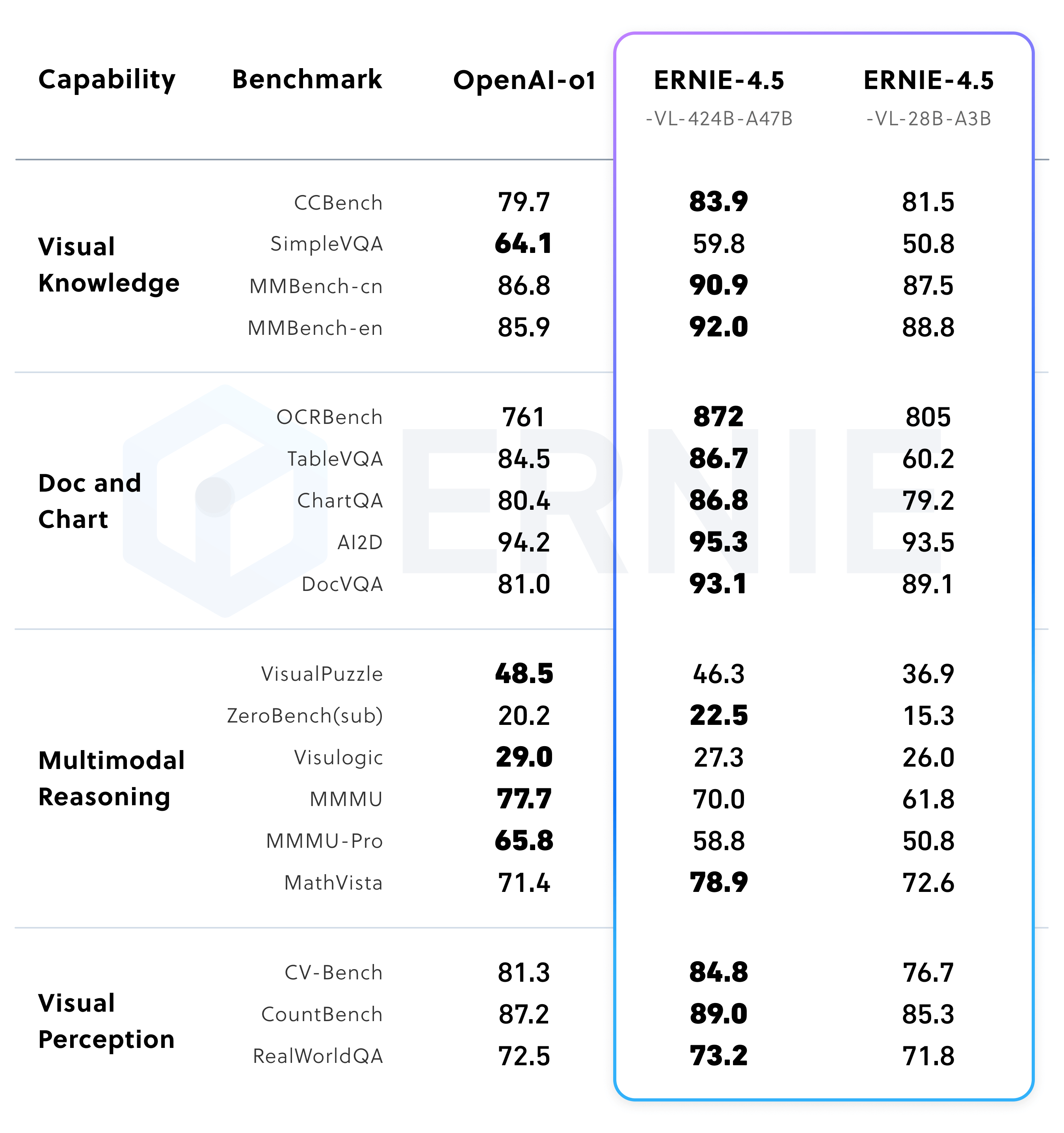
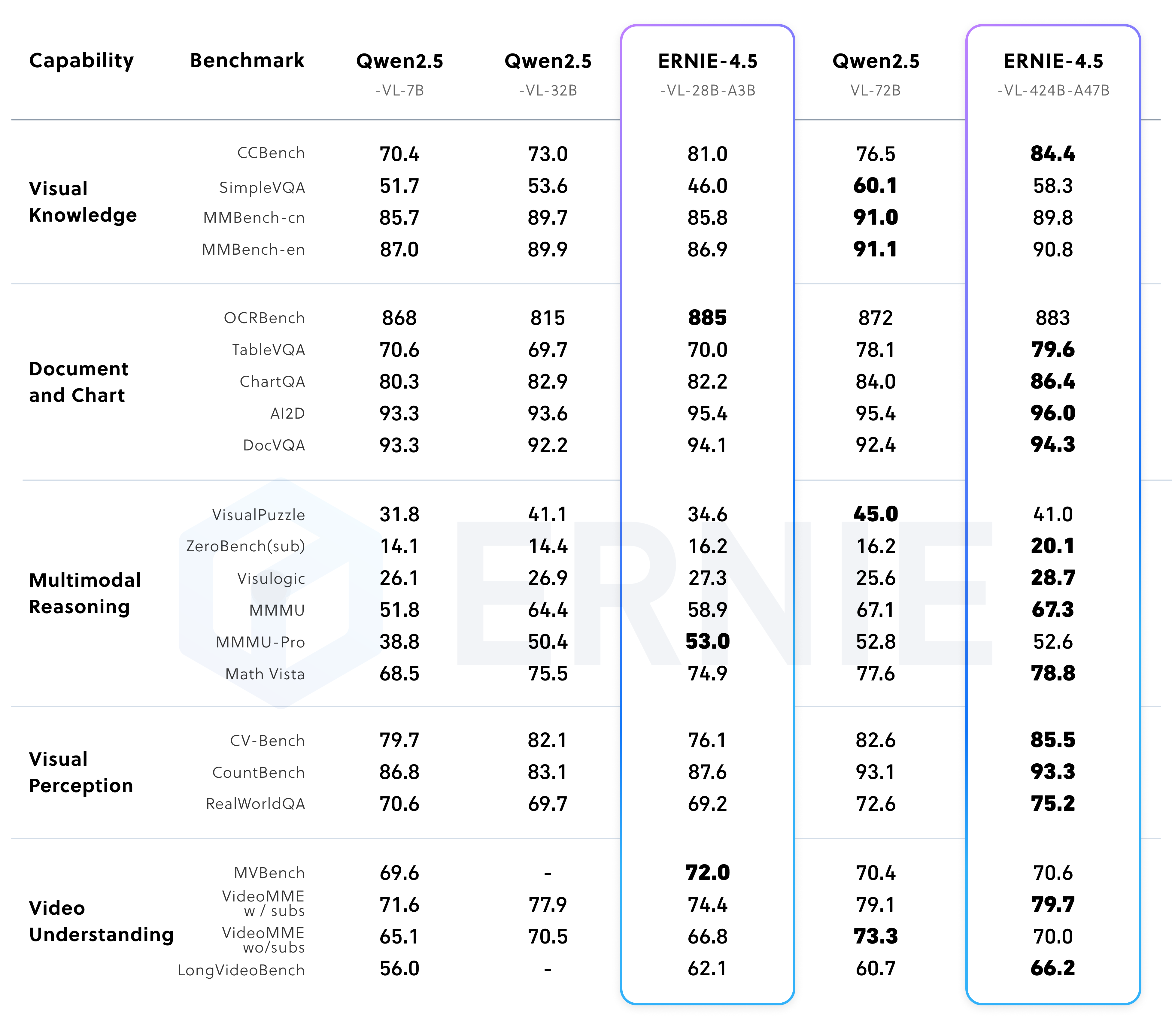
In the non-thinking mode, ERNIE-4.5-VL exhibits outstanding proficiency in visual perception, document and chart understanding, and visual knowledge, performing strongly across a range of established benchmarks. Under the thinking mode, ERNIE-4.5-VL not only demonstrates enhanced reasoning abilities compared to the non-thinking mode, but also retains the strong perception capabilities of the latter. ERNIE-4.5-VL-424B-A47B delivers consistently strong results across the various multimodal evaluation benchmarks. Its thinking mode offers a distinct advantage on challenging benchmarks such as MathVista, MMMU, and VisualPuzzle, while maintaining competitive performance on perception-focused datasets like CV-Bench and RealWorldQA. The lightweight vision-language model ERNIE-4.5-28B-A3B achieves competitive or even superior performance compared to Qwen2.5-VL-7B and Qwen2.5-VL-32B across most benchmarks, despite using significantly fewer activation parameters. Notably, our lightweight model also supports both thinking and non-thinking modes, offering functionalities consistent with ERNIE-4.5-VL-424B-A47B.
Performace of ERNIE-4.5 pre-trained models
Performance of post-trained model ERNIE-4.5-300B-A47B
Performance of post-trained model ERNIE-4.5-21B-A3B
Performance of post-trained multimodal models in thinking mode
Performance of post-trained multimodal models in non-thinking mode
Getting Started with ERNIE 4.5
The ERNIE 4.5 models are trained using the PaddlePaddle framework. The following sections detail tools and resources within the PaddlePaddle ecosystem for fine-tuning and deploying ERNIE 4.5 models.
For developers working within the PyTorch ecosystem, ERNIE 4.5 models are also available in PyTorch-compatible formats.
ERNIEKit: Fine-tuning and Alignment
ERNIEKit is an industrial-grade development toolkit for ERNIE 4.5. It provides model training and compression capabilities, including pre-training, Supervised Fine-Tuning (SFT), Low-Rank Adaptation(LoRA), Direct Preference Optimization (DPO), Quantization-Aware Training (QAT) and Post-Training Quantization (PTQ) techniques.
Usage Examples:
# Download model
huggingface-cli download baidu/ERNIE-4.5-300B-A47B-Base-Paddle \
--local-dir baidu/ERNIE-4.5-300B-A47B-Base-Paddle
# SFT
erniekit train examples/configs/ERNIE-4.5-300B-A47B/sft/run_sft_wint8mix_lora_8k.yaml \
model_name_or_path=baidu/ERNIE-4.5-300B-A47B-Base-Paddle
# DPO
erniekit train examples/configs/ERNIE-4.5-300B-A47B/dpo/run_dpo_wint8mix_lora_8k.yaml \
model_name_or_path=baidu/ERNIE-4.5-300B-A47B-Base-Paddle
For more detailed examples, please refer to ERNIEKit repository.
FastDeploy: Efficient Model Deployment
FastDeploy is an efficient deployment toolkit for large models based on PaddlePaddle. It offers an out-of-the-box, multi-hardware deployment experience with a single line of code, and its API is compatible with both vLLM and OpenAI protocols. For deploying the ERNIE 4.5 model, it provides an industrial-grade solution for multi-machine PD Disaggregation with multi-level load balancing, and it supports a wide range of acceleration technologies like low-bit quantization inference, context caching, and speculative decoding.
Local Inference Example:
from fastdeploy import LLM, SamplingParams
prompt = "Write me a poem about large language model."
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="baidu/ERNIE-4.5-0.3B-Paddle", max_model_len=32768)
outputs = llm.generate(prompt, sampling_params)
Service Deployment Example:
python -m fastdeploy.entrypoints.openai.api_server \
--model "baidu/ERNIE-4.5-0.3B-Paddle" \
--max-model-len 32768 \
--port 9904
Once the service is up and running using FastDeploy, it offers an OpenAI-compatible API, allowing for easy integration with existing tools and workflows.
For detailed documentation, installation guides, and advanced configuration options, please refer to FastDeploy repository.
License
The ERNIE 4.5 models are provided under the Apache License 2.0. This license permits commercial use, subject to its terms and conditions. Copyright (c) 2025 Baidu, Inc. All Rights Reserved.
Citation
If you find ERNIE 4.5 useful or wish to use it in your projects, please kindly cite our technical report:
@misc{ernie2025technicalreport,
title={ERNIE 4.5 Technical Report},
author={Baidu ERNIE Team},
year={2025},
eprint={},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={}
}