1. Introduction
Most existing multimodal models excel at understanding but often remain text-centric in their outputs. Attempts to enable multimodal generation usually rely on late-fusion architectures, where specialized decoders are stitched onto a pre-trained language backbone. While functional, this patchwork approach decouples understanding from generation and limits the depth of cross-modal reasoning.
ERNIE 5.0 introduces a paradigm shift. It is a Unified Multimodal Model trained from scratch to integrate text, images, video, and audio within a single autoregressive framework.
Key highlights:
- 2.4 Trillion Parameters: A massive-scale foundational model built on a unified autoregressive backbone.
- Unified Objective: We map all modalities to a shared token space and optimize them end-to-end using a unified Next-Group-of-Tokens Prediction.
- Omni-Capability: By effectively dissolving modality barriers, the model achieves seamless multimodal understanding and generation.
2. Architecture: Genuine Unification
ERNIE 5.0 adopts a fully unified approach:
- Text Modeling: Utilizes standard Next-Token Prediction (NTP), accelerated by Multi-Token Prediction (MTP) for enhanced inference throughput.
- Vision Modeling: Adopts Next-Frame-and-Scale Prediction (NFSP). Images are treated as single-frame videos, enabling the model to learn spatial (multi-scale) and temporal (multi-frame) representations simultaneously.
- Audio Modeling: Implements Next-Codec Prediction (NCP) with a depth-wise autoregressive design, hierarchically modeling audio from semantic content to fine-grained acoustic details.
This unified formulation allows the model to learn intrinsic semantic alignments among modalities rather than superficial translations.
3. Scalability and Efficiency
Training a 2.4T parameter multimodel presents significant computational challenges, which we address through two core technological innovations:
3.1 Ultra-Sparse MoE
We employ a Mixture-of-Experts (MoE) architecture featuring Modality-Agnostic Routing.
- Shared Expert Pool: Experts are not segregated by modality (e.g., “vision experts” vs “text experts”); instead, dynamic routing is driven solely by token features.
- <3% Activation Rate: Despite the trillion-parameter scale, only ~3% of parameters are activated per token. This design yields massive capacity while keeping computational costs comparable to much smaller dense models.
3.2 Elastic Training (Once-For-All)
To address diverse deployment constraints, we introduce Elastic Training, which optimizes a super-network capable of spawning multiple sub-configurations:
- Elastic Depth: Stochastic layer skipping during training.
- Elastic Width: Dynamic restriction of the active expert pool.
- Elastic Sparsity: Adaptive Top-k routing for adjustable inference cost.
This “Once-For-All” approach allows for the instant deployment of efficient sub-models without the need for resource-intensive retraining.
4. Training Methodology
4.1 Data Foundation
Our pre-training corpus consists of trillions of tokens, featuring UTF-16BE encoding for superior multilingual support. We utilize a mix of paired data (image-text, video-text) and interleaved sequences to enforce robust cross-modal contextual learning.
4.2 Training & Infrastructure
Built upon PaddlePaddle, ERNIE 5.0 adopts a customized hybrid parallel strategy to manage the ultra-sparse MoE architecture at scale. The training process is rigorously staged—extending context length from 8K to 128K—and incorporates advanced stability techniques to prevent any single modality from dominating gradient updates.
4.3 Post-Training
To align ERNIE 5.0 for complex tasks, we developed a specialized Reinforcement Learning (RL) pipeline:
- U-RB (Unbiased Replay Buffer): Addressing long-tail response inefficiency without introducing sampling bias.
- Stability Mechanisms (MISC & WPSM): Techniques to mitigate entropy collapse and focus optimization on challenging samples.
- AHRL (Adaptive Hint-based RL): A scaffolding method that provides fading “thinking skeletons” (hints) to facilitate learning on sparse-reward, hard-reasoning tasks.
5. Evaluation & Results
ERNIE 5.0 establishes new state-of-the-art benchmarks across modalities:
5.1 Language Capabilities
ERNIE 5.0 shows strong performance across both pre-training and post-training evaluations, spanning knowledge, reasoning, coding, instruction following, and agentic tool-use tasks.
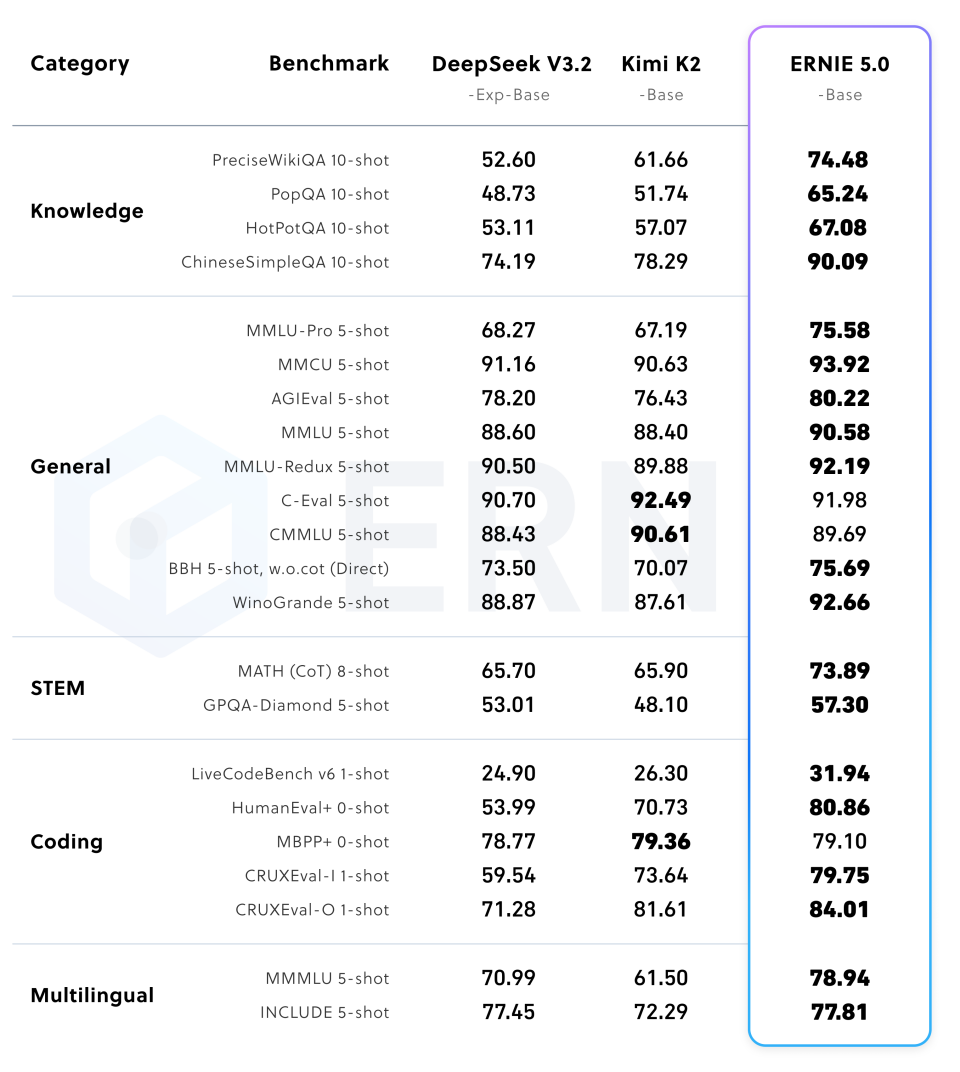 (Table 1: Pre-training comparisons)
(Table 1: Pre-training comparisons)
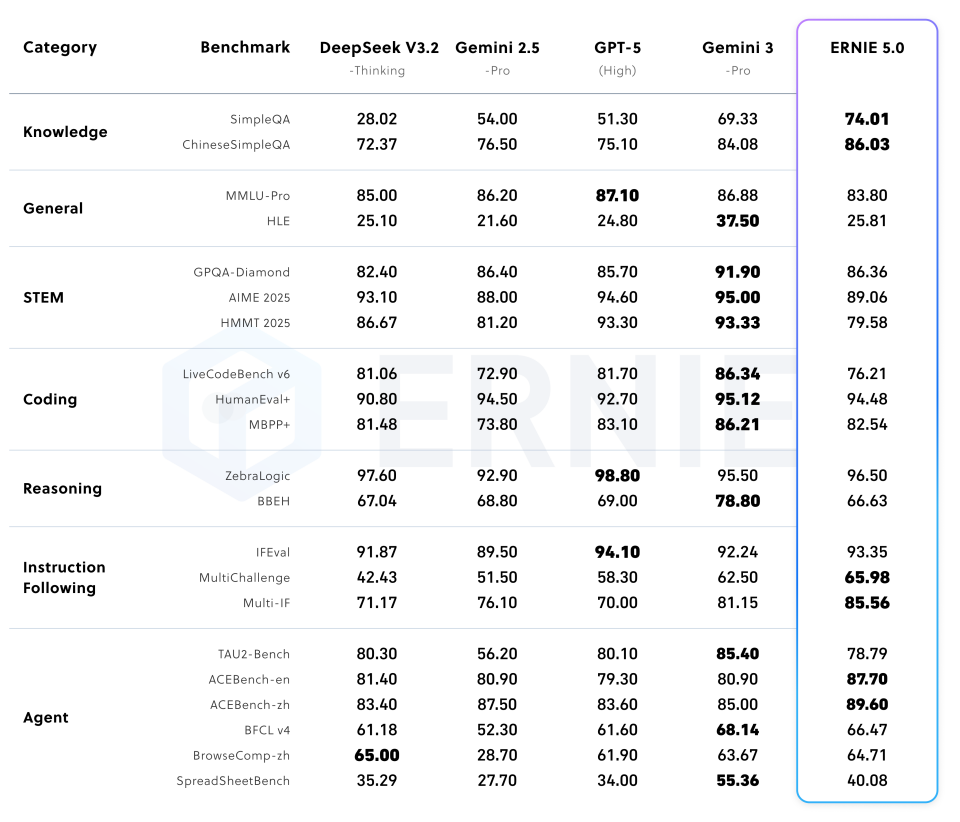 (Table 2: Post-training comparisons)
(Table 2: Post-training comparisons)
5.2 Multimodal Understanding
Demonstrates strong multimodal understanding capabilities across diverse benchmarks.
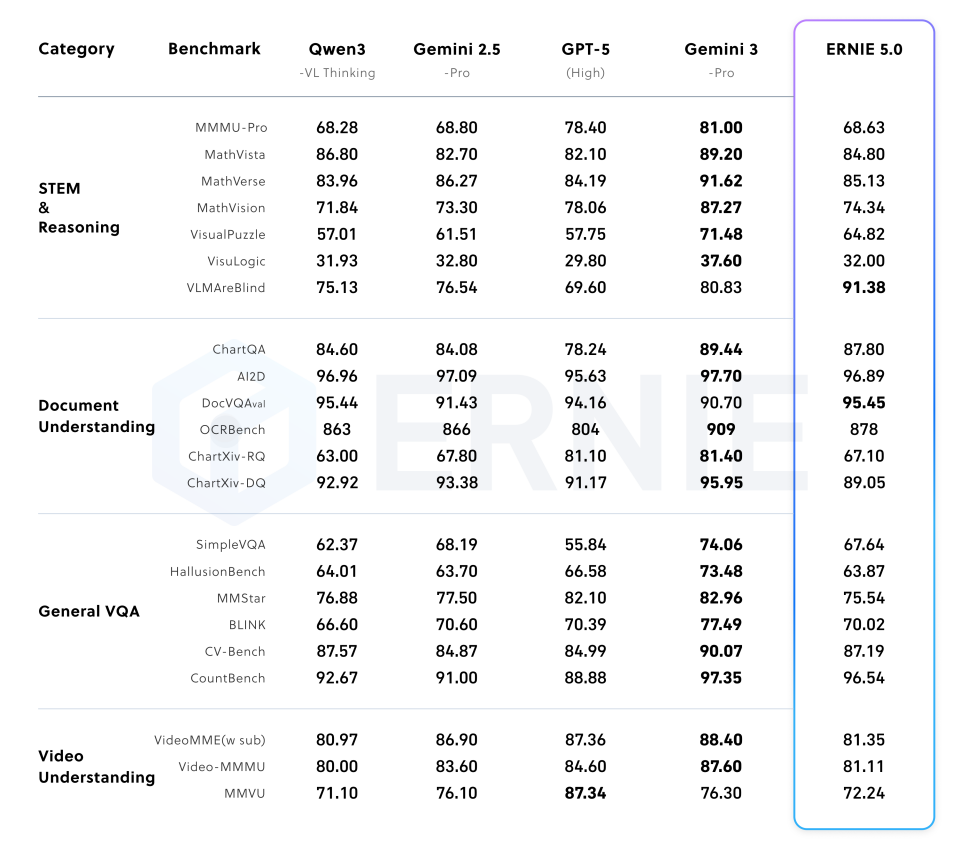 (Table 3: Multimodal Understanding)
(Table 3: Multimodal Understanding)
5.3 Generation Capabilities
Shows superior performance in visual generation tasks for both high-fidelity images and video.
 (Table 5: Image Generation)
(Table 5: Image Generation)
 (Table 6: Video Generation)
(Table 6: Video Generation)
5.4 Audio Capabilities
Achieves best-in-class results in Audio Understanding (e.g., TUT2017) and competitive Text-to-Speech performance.
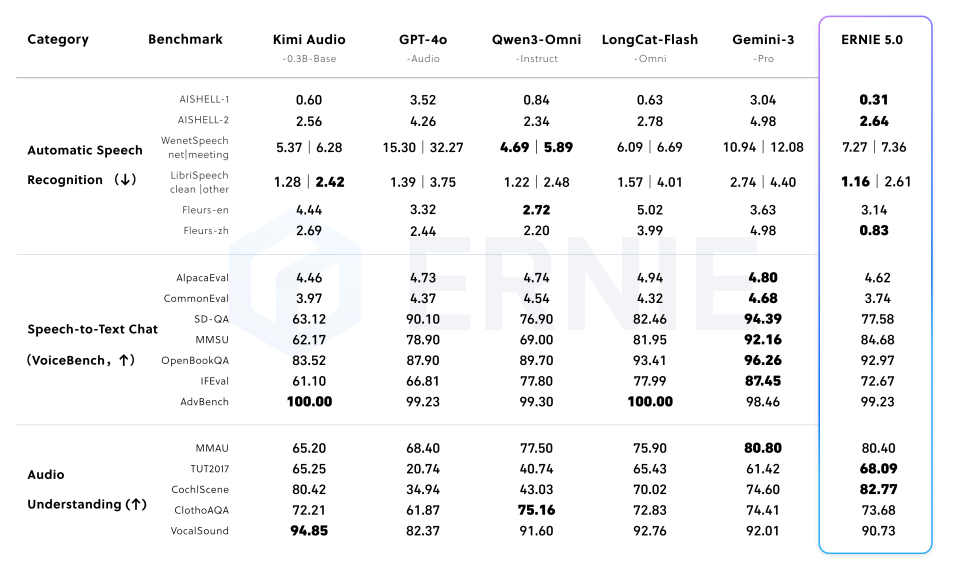 (Table 7: Audio Understanding)
(Table 7: Audio Understanding)
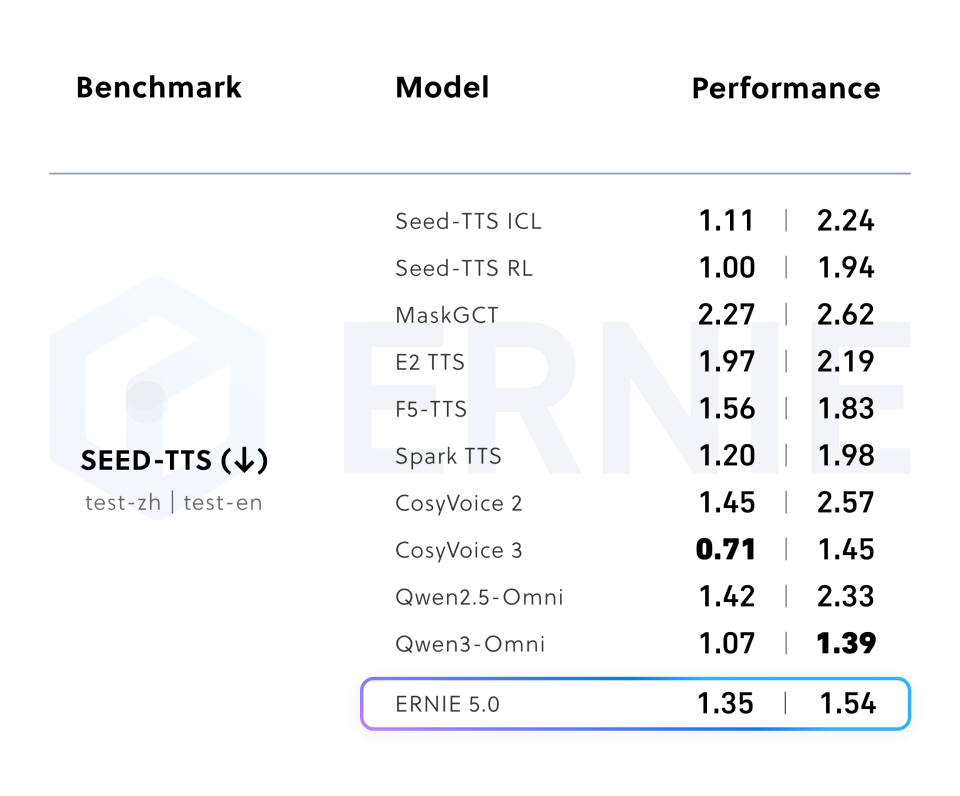 (Table 8: Text-to-Speech)
(Table 8: Text-to-Speech)
6. Conclusion
ERNIE 5.0 represents a decisive step away from the fragmented “patchwork” era of AI and toward a future of truly native multimodal intelligence. By successfully unifying understanding and generation within a single, elastic, and scalable autoregressive framework, we have laid the groundwork for systems that do not just process data, but perceive and create with the fluidity of human cognition.
Looking ahead, the innovations in Modality-Agnostic Routing and Elastic Training unlock new possibilities for deploying massive-scale intelligence across diverse environments—from cloud superclusters to edge devices—without compromising on capability. As we continue to refine this unified paradigm, ERNIE 5.0 serves as a robust foundation for the next leap in General Artificial Intelligence (AGI), where the boundaries between listening, speaking, reading, writing, and reasoning effectively dissolve.
Citation
@misc{wang2026ernie50technicalreport,
title={ERNIE 5.0 Technical Report},
author={Haifeng Wang and others},
year={2026},
eprint={2602.04705},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2602.04705}
}