1. 引言
当前大多数多模态模型虽展现出色的理解能力,但在生成端往往局限于文本模态。为了实现多模态生成,业界主流方案通常采用后融合架构,即在预训练语言主干网络上挂接专用的解码器。这类“拼接式”方案虽然有效,但导致了理解与生成的割裂,限制了跨模态推理的深度。
文心 5.0 带来了范式转变。它是原生全模态大模型,采用原生的全模态统一建模技术,将文本、图像、音频、视频联合建模,具备综合的全模态能力。
核心亮点:
- 2.4 万亿参数:基于统一自回归网络构建的超大规模基础模型。
- 统一目标:将所有模态映射至共享的符号空间,并通过统一的 下一组 Token 预测(Next-Group-of-Tokens Prediction) 任务进行端到端优化。
- 全模态能力:彻底消融模态壁垒,实现跨模态理解与生成的无缝衔接。
2. 架构:真正的统一
文心 5.0 采用原生的全模态统一建模技术:
- 文本建模:采用标准的 下一 Token 预测(Next-Token Prediction, NTP),并辅以 多 Token 预测(Multi-Token Prediction, MTP) 技术以提升推理吞吐量。
- 视觉建模:引入 下一帧与尺度预测(Next-Frame-and-Scale Prediction, NFSP)。图像被视为单帧视频,使模型能联合学习空间(多尺度)与时间(多帧)表征。
- 音频建模:实现 下一编解码预测(Next-Codec Prediction, NCP),采用深度自回归分层建模,从语义内容到细粒度声学细节进行逐级刻画。
这种统一的范式使模型能够学习模态间内在的语义对齐,而非仅仅进行表层的特征翻译。
3. 可扩展性与效率
训练 2.4 万亿参数的原生全模态大模型面临严峻的算力挑战,这也是我们通过两项核心技术创新致力解决的问题:
3.1 超稀疏 MoE
我们采用了具备 模态无关路由(Modality-Agnostic Routing) 机制的混合专家(MoE)架构。
- 共享专家池:专家不再按模态人为划分(如“视觉专家”或“文本专家”),而是完全基于 Token 特征进行动态路由匹配。
- <3% 激活率:尽管参数规模达万亿级,但每个 Token 仅激活约 3% 的参数,提供巨大模型容量的同时,将计算成本控制在与小型稠密模型相当的水平。
3.2 弹性训练(Once-For-All)
为满足多样化的部署需求,我们提出 弹性训练(Elastic Training) 策略,通过一次训练即可优化出一个能够派生多种子配置的超网络:
- 弹性深度:训练过程中随机跳过部分网络层。
- 弹性宽度:动态限制参与计算的专家池规模。
- 弹性稀疏度:通过可变 Top-k 路由机制灵活调节推理成本。
这种 “Once-For-All” 的策略支持即时导出高效的子模型,无需进行高成本的二次训练。
4. 训练方法
4.1 数据基座
预训练语料库规模达数万亿 Token,并采用 UTF-16BE 编码以提供更卓越的多语言支持。我们混合使用了配对数据(图文、视文)与交错序列数据,以增强模型跨模态上下文学习的鲁棒性。
4.2 训练基础设施
基于 飞桨,文心 5.0 采用自研的混合并行策略,在超稀疏 MoE 架构下实现了大规模稳健训练。整个训练流程采用严格的阶段式推进——上下文窗口从 8K 逐步扩展至 128K,并融合了先进的稳定性技术,有效防止单一模态主导梯度更新。
4.3 后训练
为使文心 5.0 胜任复杂的应用场景,我们构建了专门的强化学习(RL)管线:
- U-RB(无偏回放缓存,Unbiased Replay Buffer):针对长尾分布样本,解决响应效率问题且不引入采样偏差。
- 稳定机制(MISC 与 WPSM):缓解熵崩塌问题,并聚焦于难例样本的优化。
- AHRL(自适应提示强化学习,Adaptive Hint-based RL):通过逐渐退出的“思维骨架”提示,为稀疏奖励及重推理任务提供“脚手架”式引导。
5. 评测与结果
文心 5.0 在多模态基准评测上树立了新的 SOTA 标准:
5.1 文本能力
在预训练与后训练评估中,文心 5.0 在知识储备、逻辑推理、代码编程、指令遵循及智能体工具调用等任务上均展现出强劲性能。
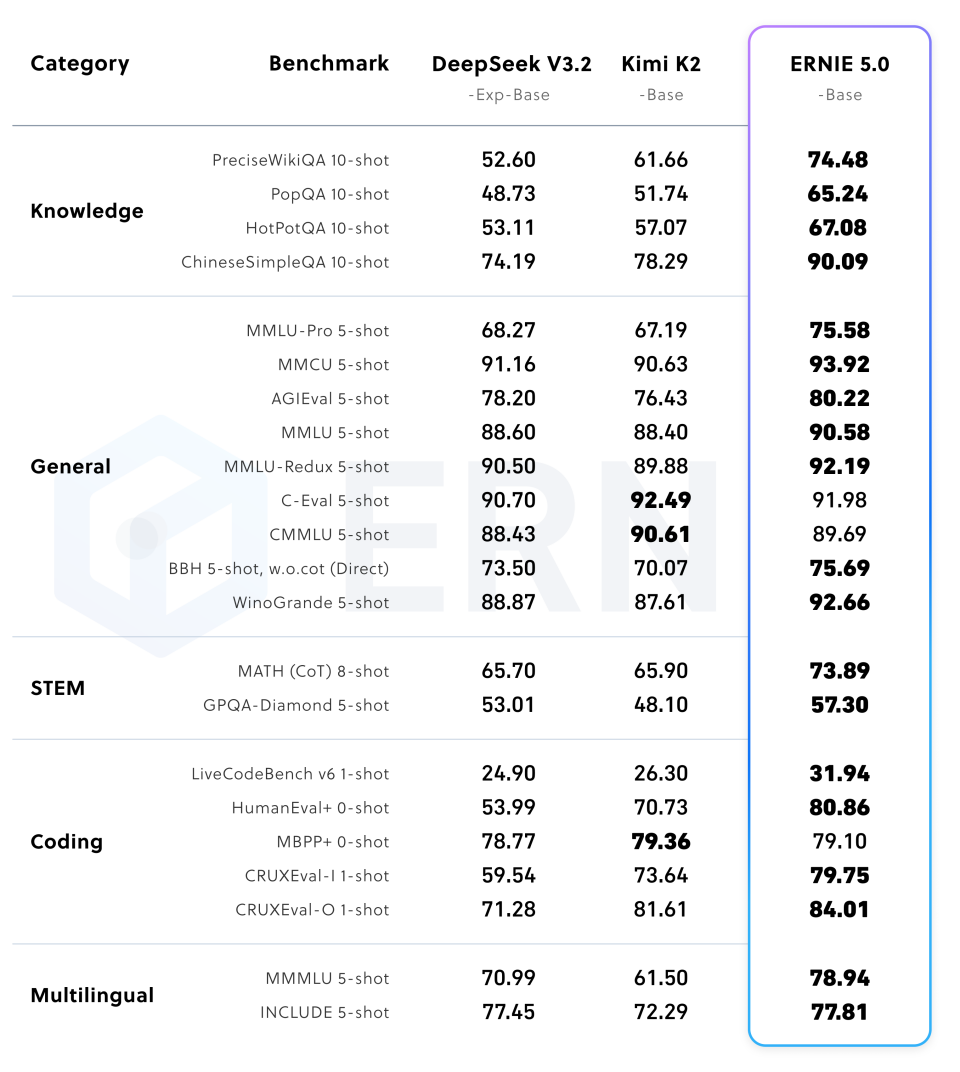 (表 1:预训练对比)
(表 1:预训练对比)
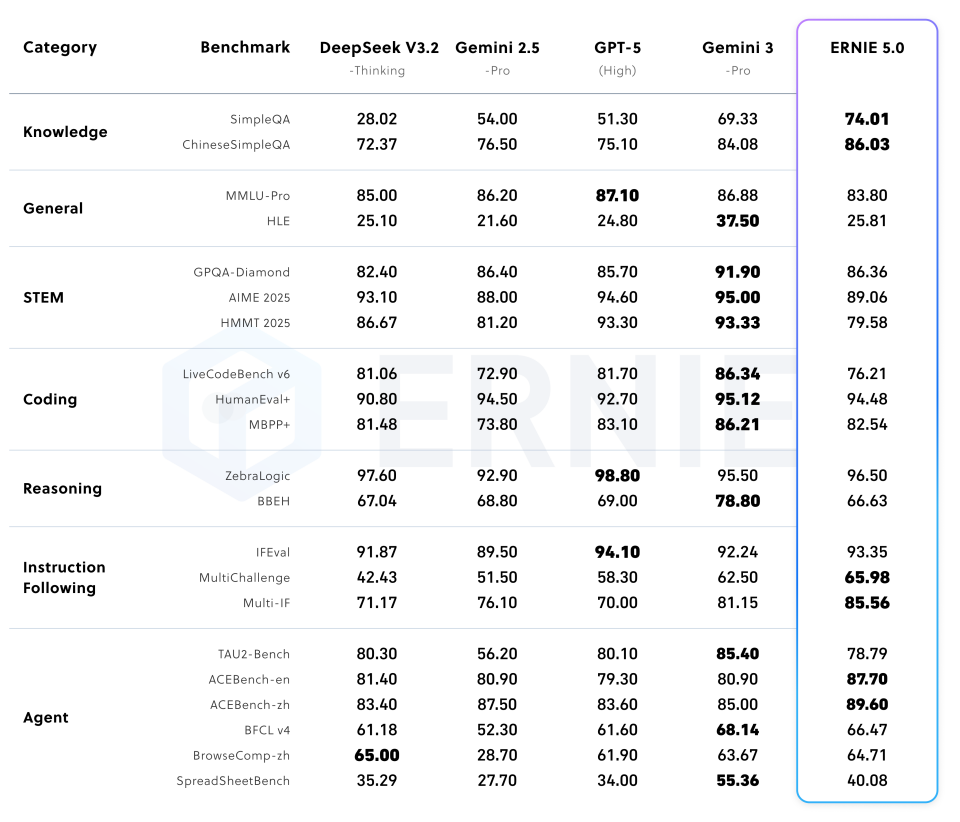 (表 2:后训练对比)
(表 2:后训练对比)
5.2 多模态理解
在多样化的基准测试中,模型展示出了卓越的多模态理解能力。
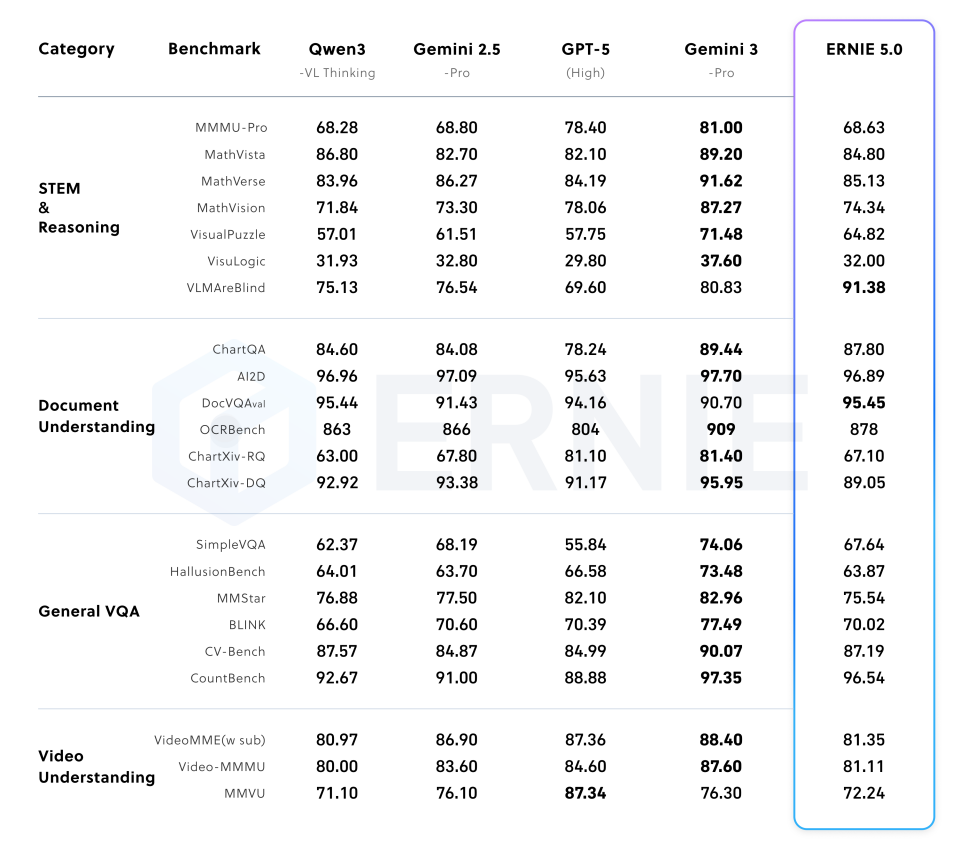 (表 3:多模态理解)
(表 3:多模态理解)
5.3 生成能力
在高保真图像生成与视频生成任务中,模型表现处于行业领先地位。
 (表 5:图像生成)
(表 5:图像生成)
 (表 6:视频生成)
(表 6:视频生成)
5.4 音频能力
在 音频理解(如 TUT2017)任务上达到业界最佳水平,并在 文本转语音 领域实现了极具竞争力的表现。
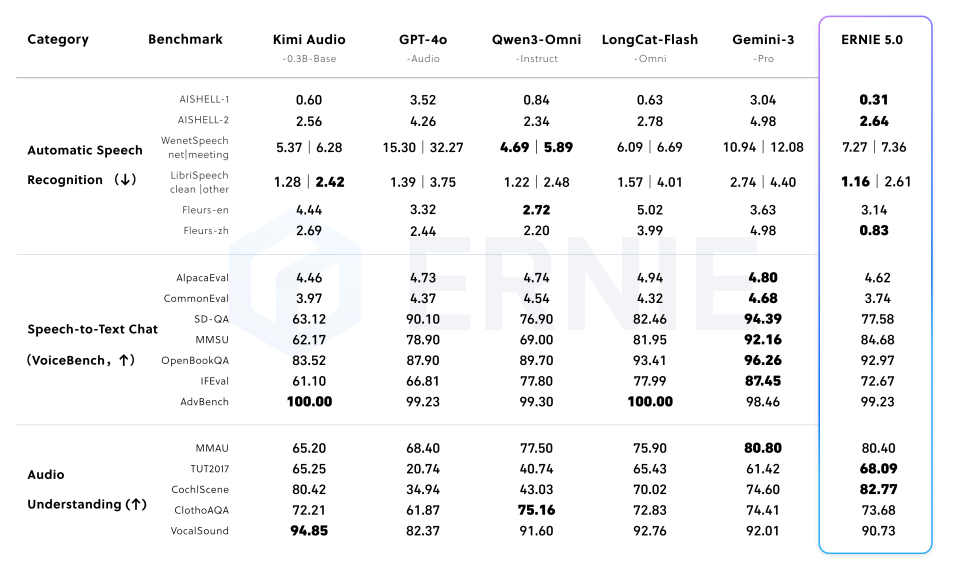 (表 7:音频理解)
(表 7:音频理解)
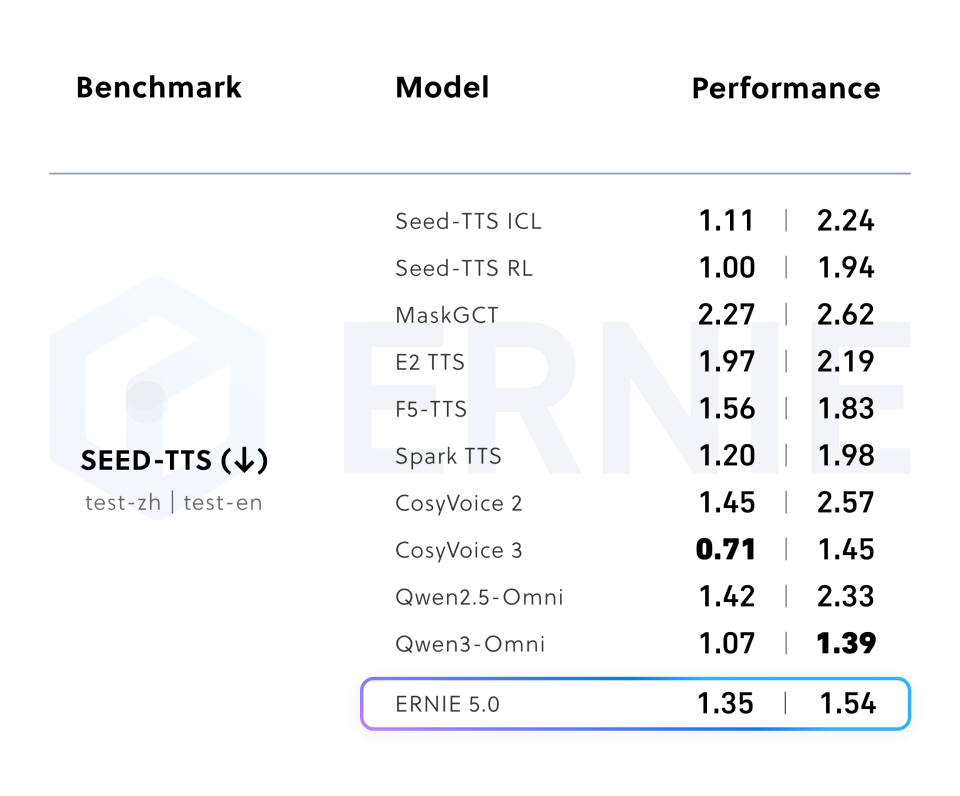 (表 8:文本转语音)
(表 8:文本转语音)
6. 结论
文心 5.0 标志着 AI 从碎片化的“拼装式”时代迈向真正原生多模态智能的关键一步。它成功在单一、弹性且可扩展的自回归框架内统一了理解与生成,为构建像人类认知那样流畅感知与创作的系统奠定了坚实基础。
展望未来,模态无关路由与弹性训练的创新,为在多样化环境中部署超大规模智能开启了新的可能——从云端超算集群到边缘设备,都能在不牺牲核心能力的前提下灵活适配。随着这一统一范式的持续打磨,文心 5.0 将作为坚实底座,推动向通用人工智能(AGI)的下一次飞跃,让“听”“说”“读”“写”“思”的界限真正消融。
@misc{wang2026ernie50technicalreport,
title={ERNIE 5.0 Technical Report},
author={Haifeng Wang and others},
year={2026},
eprint={2602.04705},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2602.04705}
}